需要将网络热门文章爬取入库
页面选择

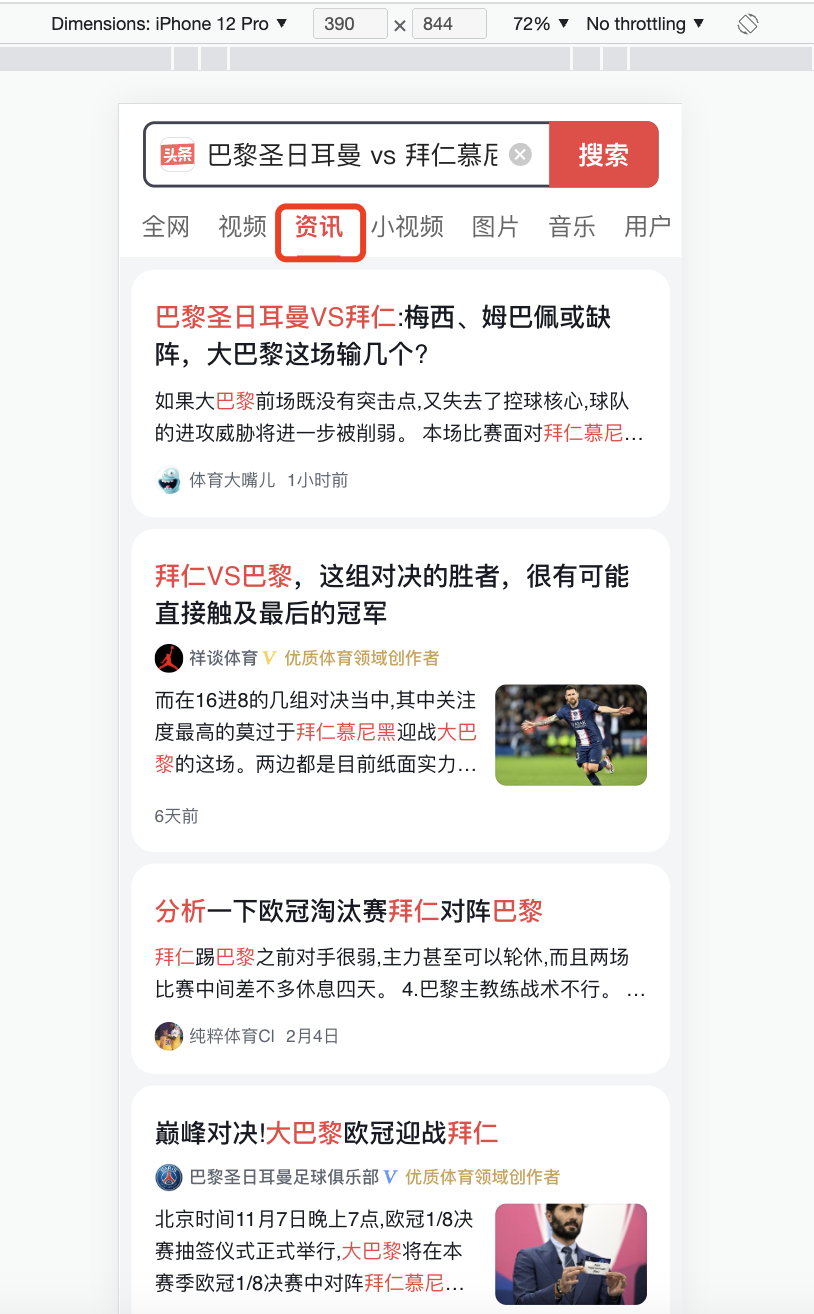
通过这个页面 能找到接口
接口里面的dom字段是html格式的,里面有文章的ID,也可以直接取文章页面;通过xpath或者re给取出来,然后requests单个文章的接口
这是文章页的API接口content字段就是,他这接口直接返回的html格式的,可以直接嵌套在html页面上。
多次访问需要验证,多请求两次可以了;可以使用代理IP,提高成功率。
import requests
import re
import json
import sys
import time
import pymysql
from pymysql.cursors import DictCursor
from pyquery import PyQuery
from db import db_ini,xxxx
re_url = re.compile(r'"(?P<url_id>\d\d\d\d\d\d\d\d\d\d\d+)"',re.S)
global_id_list = [] # 全局文章id 用于去重
def getProxyIp(): # 代理IP函数 返回代理
headers = {
"User-Agent": "Mozilla/4.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
}
**** # 代理IP具体实现的方法
req = requests.get(url,params=params,headers=headers,timeout=3,verify=False)
data = json.loads(req.text)["data"][0]
ip_add = '{}:{}'.format(data["ip"],data["port"])
# proxyMeta = "http://%(proxy)s/" % {'proxy' : "192.168.171.132:8088"}
proxyMeta = "https://%(proxy)s/" % {'proxy' : ip_add}
proxies = {
"http" : proxyMeta,
# "https" : proxyMeta
}
print("当前代理IP:{}".format(proxyMeta))
return(proxies)
def custom_time(timestamp):
# 转换成localtime
time_local = time.localtime(timestamp)
# 转换成新的时间格式(2016-05-05 20:28:54)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
return (dt)
def to_db(data=None,sql=None,type_ini=None):
conn = pymysql.connect(**xxxx("test"))
conn.autocommit(True)
cur = conn.cursor(DictCursor)
resp = db_ini(cur=cur,data=data,sql=sql,type_ini=type_ini)
cur.close()
return(resp)
def get_url(url,session):
header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Host": "so.toutiao.com",
"Pragma": "no-cache",
"Referer": "http://so.toutiao.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
}
resp = session.get(url=url,headers=header,verify = False)
try:
ret = json.loads(resp.text)
except:
print("请求接口失败")
return(False)
dom = ret["dom"] # 这里有 文章的id 需要 re取
urls = set(re_url.findall(dom)) # 集合去重
return(urls)
def get_info(urls,data,session):
header = {
"Accept": 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
"Accept-Language": 'zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7',
"Cache-Control": 'no-cache',
"Connection": "keep-alive",
"Host": 'm.toutiao.com',
"Pragma": 'no-cache',
"Sec-Fetch-Dest": 'document',
"Sec-Fetch-Mode": 'navigate',
"Sec-Fetch-Site": 'none',
"Sec-Fetch-User": '?1',
"Upgrade-Insecure-Requests": '1',
"User-Agent": 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}
count_list = []
for i in urls:
url = "https://m.toutiao.com/i{}/info/v2/?is_search_result=1&in_tfs=".format(i)
# url = "https://m.toutiao.com/i7197008126829330981/info/v2/?is_search_result=1&in_tfs="
print("文章API",url)
time.sleep(0.5)
resp = session.get(url=url,headers=header,verify = False)
ret = resp.text
try:
json_data = json.loads(ret)["data"]
except:
print("文章API错误",url)
continue
if not json_data: # 判断 data字段是否存在 如果不存在 就跳过
print("无数据")
continue
title = (json_data["title"])
publish_time = (json_data["publish_time"])
detail_source = (json_data["detail_source"])
from_url = (json_data["url"])
content = (json_data["content"])
data["article_id"] = i
data["title"] = title
data["publish_time"] = custom_time(int(publish_time))
data["detail_source"] = detail_source
data["content"] = str(PyQuery(content)).replace("'",'"')
data["from_url"] = from_url
data["database"] = "****"
data["table"] = "****"
data["unique_keys"] = ["home_team","guest_team","article_id","from_type","dv_type"]
if len(PyQuery(content).text()) < 50: # 文章内容不足50字 不要了
continue
global global_id_list # 引入全局变量
if data["article_id"] in global_id_list: # 如果文章重复就不要了
continue
global_id_list.append(data["article_id"]) # 文章ID不存在全局文章ID中 就添加
count_list.append(data["article_id"]) # 文章类型的文章统计数量
to_db(data=data,type_ini="inandto") # 写库
print(data["article_id"],"ok!")
if len(count_list) >= 2: # 文章类型的文章数量大于2就返回
return(len(count_list))
return(len(count_list)) # 整个页面都没有需要的数据 返回这个
def main(a,b):
dv_types = ["比分预测","过往战绩"]
data = {
"home_team":a,
"guest_team":b,
"from_type":1,
"dv_type":""
}
pn = 0 # 翻页统计
dv_count = 0 # 文章数量统计
req_count = 0 # requests 请求次数统计
for i in dv_types:
data["dv_type"] = i # 文章类型
while dv_count < 2: # 文章数量 不小于2 就结束
if req_count > 20:break # 请求次数 大于 20 就结束
if pn >= 30 :break # 翻页次数 大于 3 次 就结束
time.sleep(5)
session = requests.Session()
session.proxies = getProxyIp()
url = "https://so.toutiao.com/search/?keyword={}vs{} {}&pd=information&source=search_subtab_switch&from=information&runtime_tc=tt_search_m_site&format=json&count=10&offset=10&start_index={}".format(a,b,i,pn)
print("当前URL:",url)
url_id = get_url(url,session) # 获取 url_id 列表
if not url_id: # 如果返回 False 就重新请求
print("正在重新请求文章列表.")
req_count += 1 # 请求次数 + 1
continue
else:
dv_count += get_info(url_id,data,session) # 返回 文章数量 相加
pn += 10 # 有返回值 就翻页请求
if __name__ == '__main__':
print("今日头条",custom_time(int(time.time())))
print("\n")
print("\n")
print("\n")
print("\n")
t1 = int(time.time())
main(sys.argv[1],sys.argv[2])
t2 = int(time.time())
print("用时",t2-t1)
tian@tiandeMacBook-Air % python3 jinritoutiao.py 阿根廷 巴西
