需要将网络热门文章爬取入库
页面选择
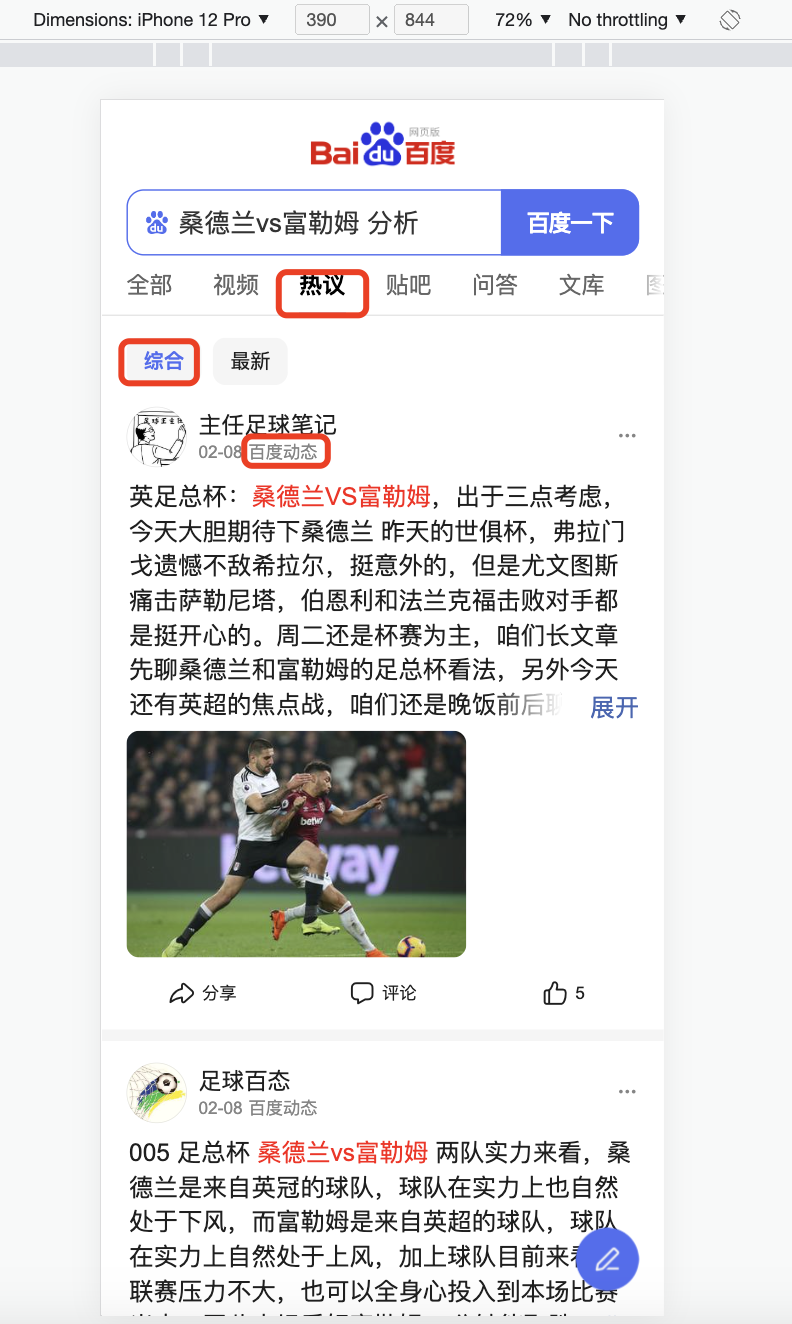

通过这个页面 能找到接口
然后就需要对接口进行加工操作了
我用python3 的 requests方法请求不成功,就改成curl了。
import re
import json
import sys
import time
import pymysql
import subprocess
from pymysql.cursors import DictCursor
from db import db_ini,xxxx
global_id_list = [] # 全局 文章 id 列表
def shell_curl(command):
res = subprocess.run(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding='utf-8',
timeout=180,
executable='/bin/bash')
if res.returncode == 0:
return(res.stdout)
else:
return(False)
def custom_time(timestamp):
# 转换成localtime
time_local = time.localtime(timestamp)
# 转换成新的时间格式(2016-05-05 20:28:54)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
return (dt)
def to_db(data=None,sql=None,type_ini=None):
conn = pymysql.connect(**xxxx("test"))
conn.autocommit(True)
cur = conn.cursor(DictCursor)
resp = db_ini(cur=cur,data=data,sql=sql,type_ini=type_ini)
cur.close()
return(resp)
def get_url(url,data):
cmd = "curl " + url # linux curl 执行 命令
dv_count = [] # 文章初始数量
resp = shell_curl(cmd) # 返回 字符串 格式
json_data = json.loads(resp)
try :
list_data = json_data["data"]["list"] # 如果百度搜索没有结果 会返回空列表 就会报错
except:
return(99) # 因为没有搜索结果 返回大于10的数字 模拟请求完成
for i in list_data: # 循环每个页面的内容
try:
if i["source"] == "百度动态": # 百度动态 = 百家号
data["article_id"] = i["commentId"]
try: # 获取标题 一般情况下是 \n\n 之前的是标题
title = re.search(r"(?P<title>.*?)\n\n",str(i["originContent"])).group("title")
except:
title = ""
try: # 获取文章内容 一般情况下是 \n\n 之后的是标题
content = ''.join(re.findall(r"\n\n(?P<content>.*)",str(i["originContent"])))
except:
content = str(i["originContent"])
if not content: # 如果 获取不到 那么内容就是空的
try:
content = ''.join(re.findall(r"\n(?P<content>.*)",str(i["originContent"])))
if not content:
content = str(i["originContent"])
except:
content = str(i["originContent"])
data["title"] = title
data["content"] = content
data["publish_time"] = custom_time(int(i["pubUnixTime"]))
data["content_url"] = json.dumps(i["originImgs"])
data["detail_source"] = i["nick"]
data["from_url"] = i["url"]
data["database"] = "****"
data["table"] = "****"
data["unique_keys"] = ["home_team","guest_team","article_id","from_type","dv_type"]
if len(content) < 50:
continue
global global_id_list # 引入全局变量
if data["article_id"] in global_id_list: # 判断 文章 ID 是否存在全局 ID 列表
continue
global_id_list.append(data["article_id"]) # 全局 ID 列表 + 1
dv_count.append(data["article_id"]) # 某个文章类型的统计 + 1
to_db(data=data,type_ini="inandto")
if len(dv_count) >= 3:
return(len(dv_count))
except:
continue
return(len(dv_count))
def main(a,b):
dv_types = ["比分预测","首发阵容"]
data = {
"home_team":a,
"guest_team":b,
"from_type":2,
}
for i in dv_types:
data["dv_type"] = i
pn = 0 # 翻页统计
dv_count = 0 # 文章数量统计
while dv_count < 3:
if pn > 30 :break
url = '\"http://m.baidu.com/sf/vsearch?word={}vs{}+{}&pd=realtime_ugc&sa=3&mod=5&p_type=1&data_type=json&atn=list&pn={}\"'.format(a,b,i,pn)
print("当前URL:",url)
dv_count += get_url(url,data) # 返回 文章数量 相加
pn += 10
time.sleep(5)
if __name__ == '__main__':
print("百度搜索",custom_time(int(time.time())))
print("\n")
print("\n")
print("\n")
print("\n")
t1 = int(time.time())
main(sys.argv[1],sys.argv[2])
t2 = int(time.time())
print("用时",t2-t1)
tian@tiandeMacBook-Air % python3 baidu.py 阿根廷 巴西
